New to Schema.Org ?
If you’re unfamiliar with Schema.org and want a quick introduction, start with these essential topics:
- What is the purpose of Schema.org? - Understanding the core mission and value
- Data model- How Schema.org structures and organizes information
Choose a section above to begin learning about Schema.org, or continue reading to understand the rationale behind using YAML-LD for schema representation.
Why Schema.org in YAML-LD ?
This website presents my initiative to represent Schema.org vocabularies using YAML-LD format. Here is also the latest published version of YAML-LD specification, published by the JSON for Linking Data Community Group. Traditional Schema.org documentation uses various formats, but YAML-LD offers distinct advantages for readability, maintainability, and integration with modern development workflows. This project explores how YAML-LD can make Schema.org more accessible and easier to work with.
What is YAML-LD ?
YAML-LD stands for YAML for Linked Data. It is simply JSON-LD expressed in YAML syntax.
To understand that, here’s the chain:
- Linked Data → a method of publishing structured, interlinked data on the web using URIs and RDF
- JSON-LD → a W3C standard that expresses Linked Data using JSON.
- YAML-LD → the same data model as JSON-LD, but written in YAML instead of JSON.
Examples
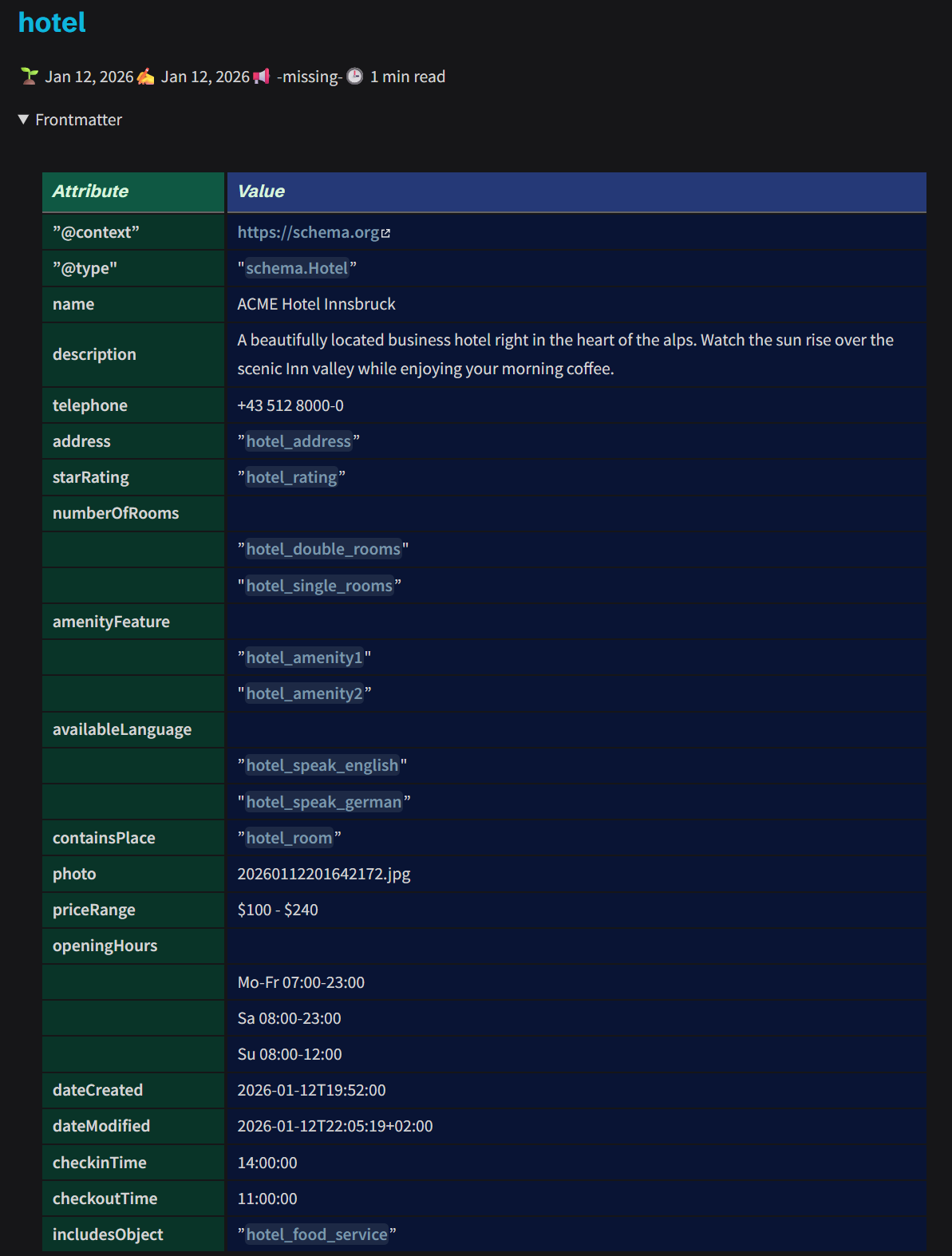
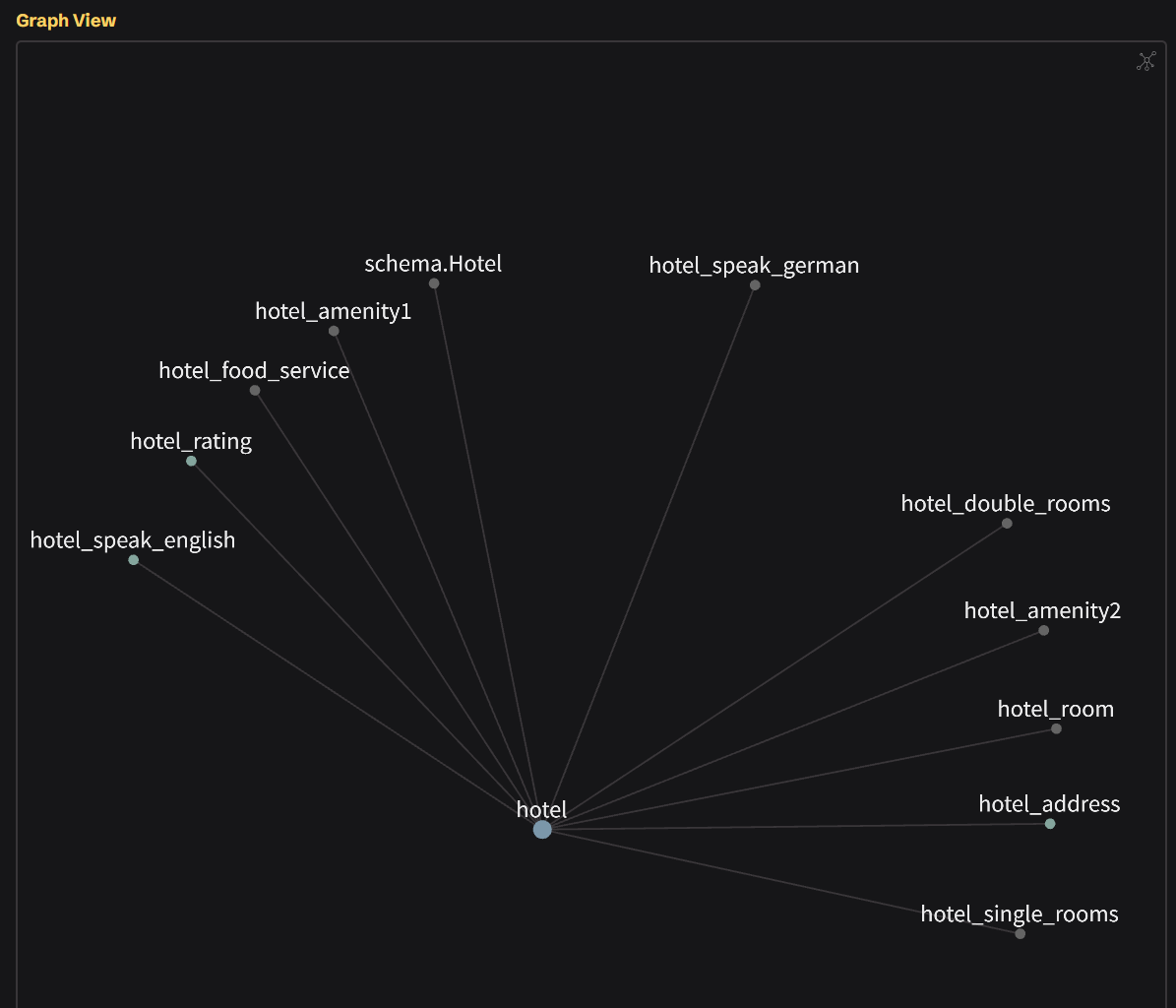

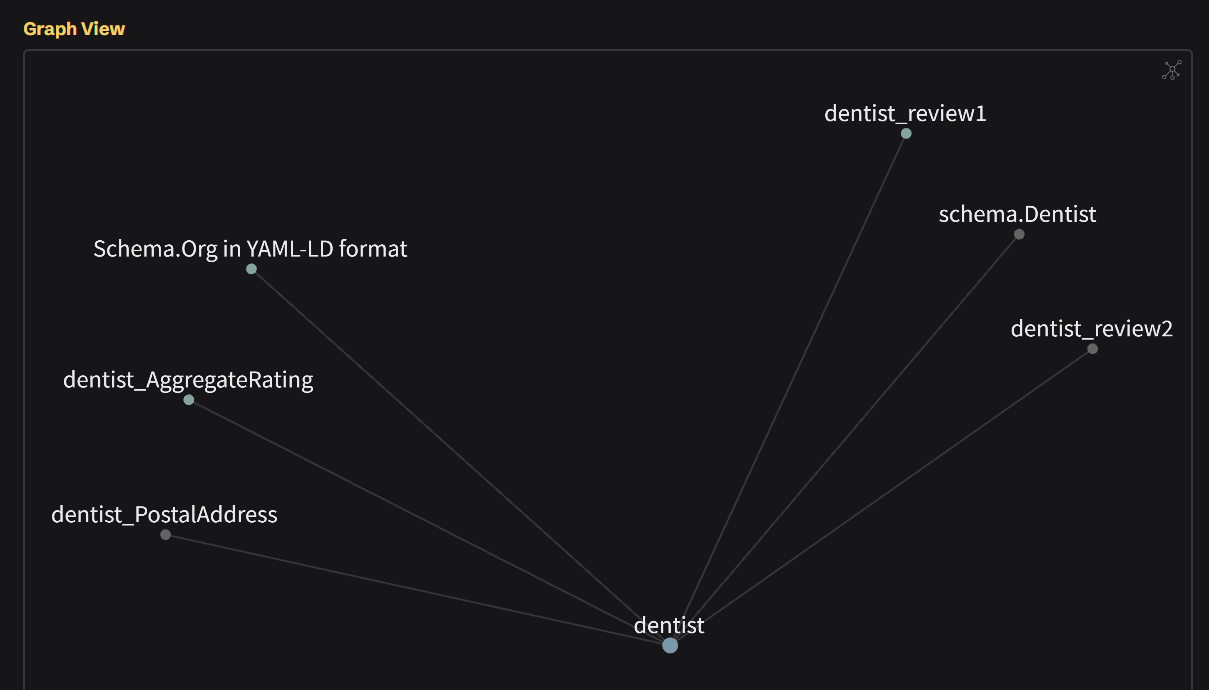
YAML-LD as a Human-Centered Authoring Layer for Schema.org
Schema.org has always been about creating shared meaning on the web rather than promoting any single technical syntax. Although the vocabulary is officially published in RDF/Turtle and widely deployed using JSON-LD, these formats are primarily designed for machines, data pipelines, and search engines. They work extremely well for processing and validation, but they are not especially comfortable for people who need to read, write, and gradually evolve schemas over time.
YAML-LD helps bridge this gap. When Schema.org is expressed in YAML-LD, particularly within a tool like Obsidian, it shifts from being only a markup layer into a human-centered knowledge base. YAML is easy to read and edit, works naturally with version control, and supports ongoing refactoring as models change. Within Obsidian, YAML can be combined with Wikilinks to interlink types, properties, and enumerations, allowing authors to navigate the vocabulary as a connected knowledge graph rather than as isolated files. This makes relationships easier to understand, encourages exploration, and surfaces dependencies naturally. From this single, interlinked source, the schema can then be reliably transformed into multiple machine-readable formats such as JSON-LD or RDF for publication and deployment.
Advantages
- human readable and curated
- Git versioned
- refactor-friendly
- publishable into multiple machine-readable formats
- interlinked (wikilinks)
Why YAML Is the Next Progressive Step
Schema.org markup formats have evolved steadily toward better machine consumption, but each step has left a gap on the human side of authoring and understanding data.
Microdata was the earliest approach, embedding semantics directly into HTML. While easy to start with, it tightly coupled data to page structure, making reuse, refactoring, and large-scale modelling difficult. It treated structured data as a lightweight annotation rather than as data that could stand on its own.
RDFa brought stronger semantic foundations by aligning markup with RDF and linked data principles. It improved rigor and interoperability, but at the cost of verbosity and complexity. Authors had to work inside HTML, and the cognitive overhead limited its practical adoption beyond specialists.
JSON-LD finally decoupled structured data from HTML and became the dominant format for deployment. It is clean, predictable, and ideal for search engines and APIs. However, JSON-LD is optimized for publishing finished data, not for exploring, designing, or evolving a vocabulary.
YAML fits naturally as the next step because it shifts focus upstream to human understanding. It provides a clear, readable authoring format where Schema.org vocabularies can be modelled and maintained first, then reliably transformed into JSON-LD or RDF for machine consumption. YAML does not replace JSON-LD or RDF, it precedes them.
YAML-LD as a Bridge, Not a Competitor
YAML-LD is not a replacement for:
- RDF/Turtle (canonical schema)
- JSON-LD (deployment format)
- Microdata/RDFa (inline markup)
Instead, YAML-LD is:
- the authoring format
- the thinking format
- the collaboration format
Conclusion
Schema.org started as a way to help machines understand web pages.
YAML-LD allows it to evolve into a way for humans to understand schemas.
By using:
- YAML-LD for modelling
- Obsidian for editing
- Static Site Generators for publishing
…we unlock a workflow where Schema.org becomes:
- explorable
- maintainable
- community-friendly
YAML-LD is the missing human layer in structured data.